
The data used here is from the 2004 Olympic Games. We are going to see if there is a correlation between the weights that a competitive lifter can lift in the snatch event and what that same competitor can lift in the clean and jerk event.
We will use a response variable of "clean" and a predictor variable of "snatch".
The heaviest weights (in kg) that men who weigh more than 105 kg were able to lift are given in the table.
| Age | Body | Snatch | Clean | Total |
|---|---|---|---|---|
| 26 | 163.0 | 210.0 | 262.5 | 472.5 |
| 30 | 140.7 | 205.0 | 250.0 | 455.0 |
| 22 | 161.3 | 207.5 | 240.0 | 447.5 |
| 27 | 118.4 | 200.0 | 240.0 | 440.0 |
| 23 | 125.1 | 195.0 | 242.5 | 437.5 |
| 31 | 140.4 | 190.0 | 240.0 | 430.0 |
| 32 | 158.9 | 192.5 | 237.5 | 430.0 |
| 22 | 136.9 | 202.5 | 225.0 | 427.5 |
| 32 | 145.3 | 187.5 | 232.5 | 420.0 |
| 27 | 124.3 | 190.0 | 225.0 | 415.0 |
| 20 | 142.7 | 185.0 | 220.0 | 405.0 |
| 29 | 127.7 | 170.0 | 215.0 | 385.0 |
| 23 | 134.3 | 160.0 | 210.0 | 370.0 |
| 18 | 137.7 | 155.0 | 192.5 | 347.5 |
The first rule in data analysis is to make a picture. In this case, a scatter plot is appropriate.
You can see from the data that there appears to be a linear correlation between the clean & jerk and the snatch weights for the competitors, so let's move on to finding the correlation coefficient.
Here is the Minitab output.
Pearson correlation of snatch and clean = 0.888
P-Value = 0.000
The Pearson's correlation coefficient is r = 0.888. Remember that number, we'll come back to it in a moment.
For now, the p-value is 0.000. Every time you have a p-value, you have a hypothesis test, and every time you have a hypothesis test, you have a null hypothesis. The null hypothesis here is H0: ρ = 0, that is, that there is no significant linear correlation.
The p-value is the chance of obtaining the results we obtained if the null hypothesis is true and so in this case we'll reject our null hypothesis of no linear correlation and say that there is significant positive linear correlation between the variables.
Let's start off with the descriptive statistics for the two variables. Remember, our predictor (x) variable is snatch and our response variable (y) is clean.
Variable N Mean SE Mean StDev Minimum Q1 Median Q3 Maximum
snatch 14 189.29 4.55 17.02 155.00 181.25 191.25 203.13 210.00
clean 14 230.89 4.77 17.86 192.50 218.75 235.00 240.63 262.50
The following explanation assumes the regression equation is y = b0 + b1x.
The formula for the slope is b1 = r (sy / sx).
For our data, that would be b1 = 0.888 ( 17.86 / 17.02 ) = 0.932.
Since the best fit line always passes through the centroid of the data, the y-intercept, b0, is found by substituting the slope just found and the means of the two variables into the regression equation and solving for b0.
230.89 = b0 + 0.932 ( 189.29 )
Solving for b0 gives the constant of 54.47.
So we can write the regression equation as clean = 54.47 + 0.932 snatch.
Here is the regression analysis from Minitab.
The regression equation is
clean = 54.6 + 0.931 snatch Predictor Coef SE Coef T P
Constant 54.61 26.47 2.06 0.061
snatch 0.9313 0.1393 6.69 0.000 S = 8.55032 R-Sq = 78.8% R-Sq(adj) = 77.1% Analysis of Variance Source DF SS MS F P
Regression 1 3267.8 3267.8 44.70 0.000
Residual Error 12 877.3 73.1
Total 13 4145.1
Notice that the regression equation we came up with is pretty close to what Minitab calculated. Ours is off a little because we used rounded values in calculations, so we'll go with Minitab's output from here on, but that's the method you would go through to find the equation of the regression equation by hand.
Let's go through and look at this information and how it ties into the ANOVA table.
A quick note about the table of coefficients, even though that's not what we're really interested in here.
Predictor Coef SE Coef T P
Constant 54.61 26.47 2.06 0.061
snatch 0.9313 0.1393 6.69 0.000
The "Coef" column contains the coefficients from the regression equation. The 54.61 is the constant (displayed as 54.6 in the previous output) and the coefficient on snatch of 0.9313 is the slope of the line.
The "SE Coef" stands for the standard error of the coefficient and we don't really need to concern ourselves with formulas for it, but it is useful in constructing confidence intervals and performing hypothesis tests.
Speaking of hypothesis tests, the T is a test statistic with a student's t distribution and the P is the p-value associated with that test statistic.
Every hypothesis test has a null hypothesis and there are two of them here since we have two hypothesis tests.
The model for the regression equation is y = β0 + β1 x + ε where β0 is the population parameter for the constant and the β1 is the population parameter for the slope and ε is the residual or error term. The b0 and b1 are just estimates for β0 and β1.
The null hypothesis for the constant row is that the constant is zero, that is H0: β0 = 0 and the null hypothesis for the snatch row is that the coefficient is zero, that is H0: β1 = 0. If the coefficient is zero, then the variable (or constant) doesn't appear in the model since it is multiplied by zero. If it doesn't appear in the model, then you get a horizontal line at the mean of the y variable. That's the case of no significant linear correlation.
So, another way of writing the null hypothesis is that there is no significant linear correlation. Notice that's the same thing we tested when we looked at the p-value from the correlation section. For that reason, the p-value from the correlation coefficient results and the p-value from the predictor variable row of the table of coefficients will be the same -- they test the same hypothesis.
The t test statistic is t = ( observed - expected ) / (standard error ). Since the expected value for the coefficient is 0 (remember that all hypothesis testing is done under the assumption that the null hypothesis is true and the null hypothesis is that the β is 0), the test statistic is simple found by dividing the coefficient by the standard error of the coefficient.
Go ahead, test it. 54.61 / 26.47 = 2.06 and 0.9313 / 0.1393 = 6.69. Pretty cool, huh?
There is one kicker here, though. The t distribution has df = n-2. That's because there are two parameters we're estimating, the slope and the y-intercept.
One further note, even though the constant may not be significantly different from 0 (as in this case with a p-value of 0.061, we marginally retain the null hypothesis that β0 = 0), we usually don't throw it out in elementary statistics because it messes up all the really cool formulas we have if we do.
Okay, I'm done with the quick note about the table of coefficients. On to the good stuff, the ANOVA.
The sources of variation when performing regression are usually called Regression and Residual. Regression is the part that can be explained by the regression equation and the Residual is the part that is left unexplained by the regression equation. This is what we've been calling the Error throughout this discussion on ANOVA, so keep that in mind. Notice that Minitab even calls it "Residual Error" just to get the best of both worlds in there.
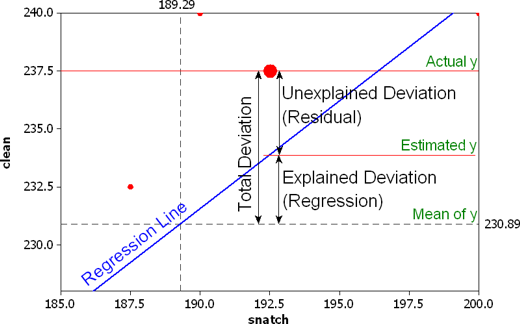 The picture to right may help explain all this. It takes one data point, for
Shane Hamman of the United States who snatched 192.5 kg and lifted 237.5 kg
in the clean and jerk.
The picture to right may help explain all this. It takes one data point, for
Shane Hamman of the United States who snatched 192.5 kg and lifted 237.5 kg
in the clean and jerk.
The centroid (center of the data) is the intersection of the two dashed lines.
The blue line is the regression line, which gives us predicted values for y.
The total deviation from the mean is the difference between the actual y value and the mean y value. In this case, that difference is 237.5 - 230.89 = 6.61. Part of that 6.61 can be explained by the regression equation. The estimated value for y (found by substituting 192.5 for the snatch variable into the regression equation) is 233.89. So the amount of the deviation that can be explained is the estimated value of 233.89 minus the mean of 230.89 or 3. The residual is the difference that remains, the difference between the actual y value of 237.5 and the estimated y value of 233.89; that difference is 3.61.
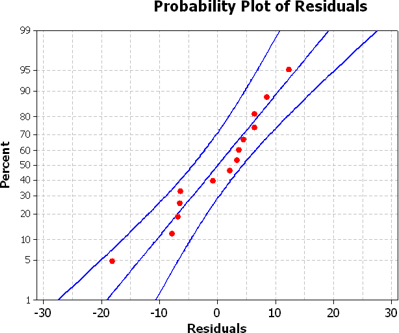 Now is as good of time as any to talk about the residuals. Here are the residuals
for all 14 weight lifters.
Now is as good of time as any to talk about the residuals. Here are the residuals
for all 14 weight lifters.
12.3164, 4.4727, -7.8555, -0.8709, 6.2855, 8.4419, 3.6137, -18.1991, 3.2701, -6.5581, -6.9017, 2.0675, 6.3803, -6.4633
The residuals are supposed to be normally distributed. As you can see from the normal probability plot, the residuals do appear to have a normal distribution.
If you simply add the residuals together, then you get 0 (possibly with roundoff error). That's not a coincidence, it always happens. That's why the sum of the residuals is absolutely useless as anything except for a check to make sure we're doing things correctly.
So, what do we do? We square each value and then add them up.
Wait a minute, what are we doing? We're finding the sum of the squares of the deviations ... Hey! That's a variation.
Yep, that's right, we're finding variations, which is what goes in the SS column of the ANOVA table. There are two sources of variation, that part that can be explained by the regression equation and the part that can't be explained by the regression equation.
Here's how the breakdown works for the ANOVA table.
| Source | SS | df |
|---|---|---|
| Regression (Explained) |
# of parameters - 1 always 1 for simple regression |
|
| Residual / Error (Unexplained) |
sample size - # of parameters n - 2 for simple regression |
|
| Total | sample size - 1 n - 1 |
Some notes on the degrees of freedom.
The df(Reg) is one less than the number of parameters being estimated. For simple regression, there are two parameters, the constant β0 and the slope β1, so there are always 2-1 = 1 df for the regression source.
The df(Res) is the sample size minus the number of parameters being estimated. For simple regression, there are two parameters so there are n-2 df for the residual (error) source.
The df(Total) is one less than the sample size, so there are n-1 df for the total df.
The F test statistic has df(Regression) = 1 numerator degrees of freedom and df(Residual) = n - 2 denominator degrees of freedom. The p-value is the area to the right of the test statistic.
Since there is a test statistic and p-value, there must be a hypothesis test. The null hypothesis is that the slope is zero, H0: β1 = 0. If that's true, then there is no linear correlation. That's the same thing we tested with the correlation coefficient and also with the table of coefficients, so it's not surprising that once again, we get the same p-value. In this particular problem, that's not so obvious since the p-value is 0.000 for all of them, just take my word for it :)
Do you remember when we said that the MS(Total) was the value of s2, the sample variance for the response variable? For our data, the MS(Total), which doesn't appear in the ANOVA table, is SS(Total) / df(Total) = 4145.1 / 13 = 318.85.
When you take the standard deviation of the response variable (clean) and square it, you get s2 = 17.862 = 318.98. The slight difference is again due to rounding errors.
The Coefficient of Determination is the percent of variation that can be explained by the regression equation. It's abbreviated r2 and is the explained variation divided by the total variation.
The variations are sum of squares, so the explained variation is SS(Regression) and the total variation is SS(Total).
Coefficient of Determination = r2 = SS(Regression) / SS(Total)
There is another formula that returns the same results and it may be confusing for now (until we visit multiple regression), but it's
Coefficient of Determination = r2 = ( SS(Total) - SS(Residual) ) / SS(Total)
For our data, the coefficient of determination is 3267.8 / 4145.1 = 0.788. Notice this is the value for R-Sq given in the Minitab output between the table of coefficients and the Analysis of Variance table.
S = 8.55032 R-Sq = 78.8% R-Sq(adj) = 77.1%
But why is it called r2? Well, our value for the correlation coefficient was r = 0.888 and 0.8882 is 0.788544 = 78.8%. Does the coolness ever end?
Remember how I mentioned the multiple regression coming up? The formula for the Adjusted R2 is the same as the second one for r2 except you use the variances (MS) instead of the variations (SS).
Adjusted R2 = ( MS(Total) - MS(Residual) ) / MS(Total)
Adjusted R2 = ( 318.85 - 73.1 ) / 318.85 = 0.771 = 77.1%
One caveat, though. The S = 8.55032 is not the same as the sample standard deviation of the response variable. It is more appropriately called se, known as the standard error of the estimate or residual standard error. That value of se = 8.55032 is the square root of the MS(error). The square root of 73.1 is 8.55.
Wow! There is a lot of good information there, but the only real difference in how the ANOVA table works in how the sum of squares and degrees of freedom are computed. We'll leave the sum of squares to technology, so all we really need to worry about is how to find the degrees of freedom.
df(Regression) = # of parameters being estimated - 1 = 2 - 1 = 1
df(Residual) = sample size - number of parameters = n - 2