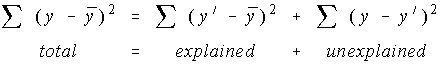
The coefficient of determination is ...
What's all this variation stuff?
Every sample has some variation in it (unless all the values are identical, and that's unlikely to happen). The total variation is made up of two parts, the part that can be explained by the regression equation and the part that can't be explained by the regression equation.
Please note that some texts use y-hat instead of y-prime.
Well, the ratio of the explained variation to the total variation is a measure of how good the regression line is. If the regression line passed through every point on the scatter plot exactly, it would be able to explain all of the variation. The further the line is from the points, the less it is able to explain.
The coefficient of non-determination is ...
Recall from earlier that a variance was a variation divided by its degrees of freedom. That means that the variation is the degrees of freedom times the variance. So, the quickest way to find the total variation is to take the variance for y (notice these are all in terms of y) and multiply by it by its degrees of freedom, df = n-1.
Wait? Why is the df = n-1? Earlier in this chapter, even later on this page, it was df=n-2. Why is it back to n-1 right now? Well, we're only talking about y, so there is only one variable involved, hence n-1. In the other places, we were considering both x and y, so there were two variables, and the degrees of freedom were n-2.
Really, it all makes sense. Math is not a bunch of rules that seemingly appeared out of nowhere and filled with contradictions and exceptions.
The coefficient of non-determination was used in the t-test to see if there was significant linear correlation. It was the in the numerator of the standard error formula.
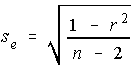 The standard error of the estimate is the square root of the coefficient of
non-determination divided by its degrees of freedom.
The standard error of the estimate is the square root of the coefficient of
non-determination divided by its degrees of freedom.
Please notice something else about the standard error of the estimate. When we were performing a hypothesis test using the t-test to see if there was any linear correlation, our test statistic was the observed value of r minus the expected value of rho (0), all over the standard error. We've seen that before when using the Z or T tests.
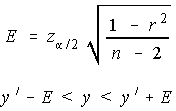 The following only works when the sample size is large. Large in
this instance is usually taken to be more than 100. We're not going
to cover this in class, but is provided here for your information. The
maximum error of the estimate is given, and this maximum error of
the estimate is subtracted from and added to the estimated value of y.
The following only works when the sample size is large. Large in
this instance is usually taken to be more than 100. We're not going
to cover this in class, but is provided here for your information. The
maximum error of the estimate is given, and this maximum error of
the estimate is subtracted from and added to the estimated value of y.